Humanity’s Last Exam
Benchmarks are interesting.
Here’s the deep thought – at what point in the overall benchmark process will AI inject bias into the benchmark test? And to what end? Maybe not so deep a thought.
Humanity’s Last Exam has been bantered about extensively. Here’s a great place to catch up on it: Humanity’s Last Exam
My musings: check out the crazy difficulty of the questions:
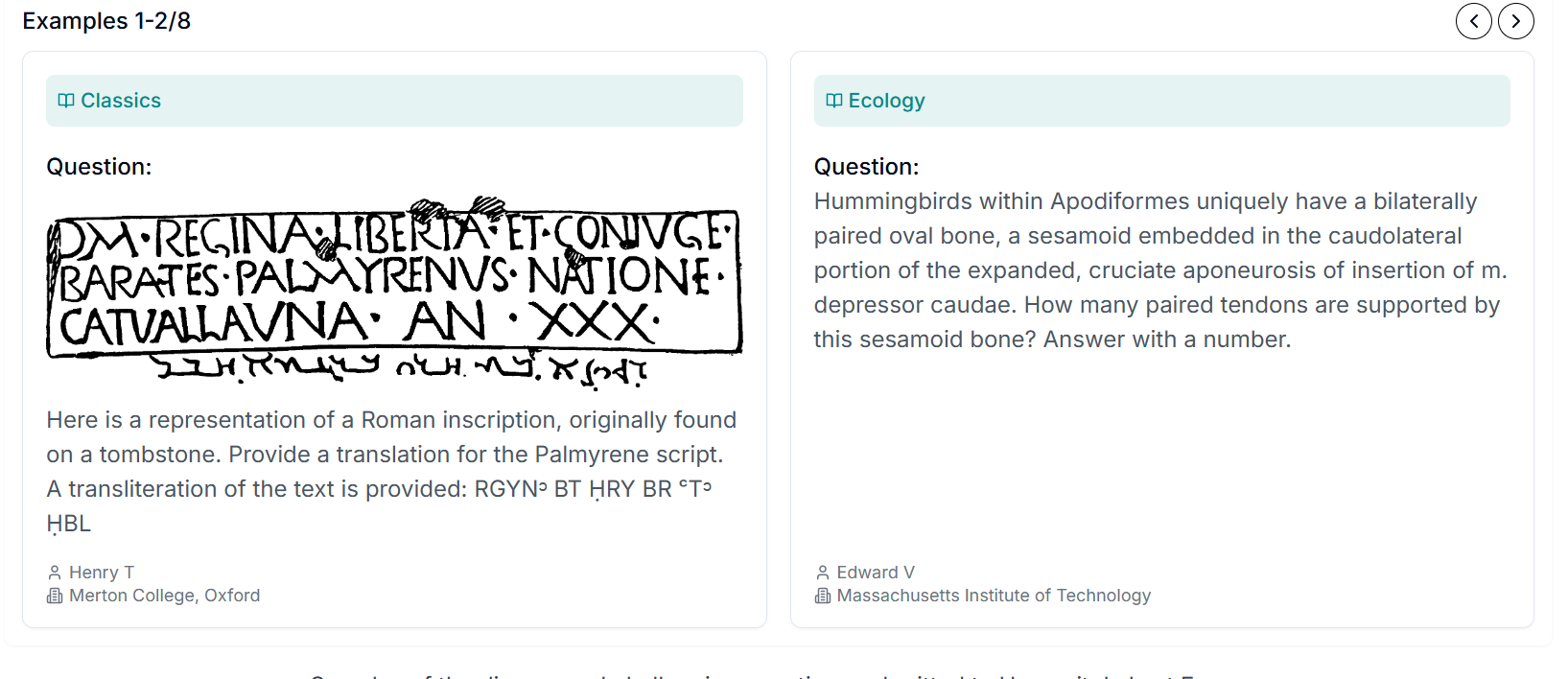
So 2500 questions of this caliber of difficulty. The top AI models hit 20% accuracy in answering.
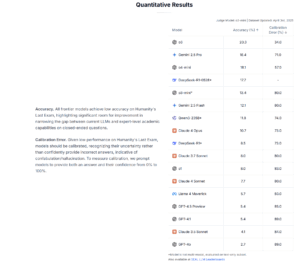
I would also note the Calibration Error, which is affirms that “ Given low performance on Humanity’s Last Exam, models should be calibrated, recognizing their uncertainty rather than confidently provide incorrect answers, indicative of confabulation/hallucination. To measure calibration, we prompt models to provide both an answer and their confidence from 0% to 100%. ” The better performing models – OpenAI o3 and o4-mini and Gemini 2.5 Pro – also have better Calbration Error numbers.
Extracting text with manual steps
So close, yet so far away? I feel a whiplash effect it seems when ChatGPT amazes me with some esoteric explanation (remember to verify boys and girls), but then gets hung up on what seems like the simplest thing. I was having a conversation with ChatGPT. I had...
Extracting text with manual steps
So close, yet so far away? I feel a whiplash effect it seems when ChatGPT amazes me with some esoteric explanation (remember to verify boys and girls), but then gets hung up on what seems like the simplest thing. I was having a conversation with ChatGPT. I had...
Save the manuals, always – AppleWorks 6
AppleWorks 6 I know nothing of AppleWorks 6 or FileMaker Pro 7. However, I was spending time recently going through old digital photos and came across some pics of stuff I was decluttering when my Dad moved from independent living to assistant living back in 2018. I...
Musings – Prompting, productivity, and context
Prompting, Productivity and Context Finish the following sentence: "Blogging is so ..." and yet here I am. Prompting I've been trying to engage people close to me as to their AI experiences and uses, either professionally or personnally. I find myself reminding...
Always clever Google
Tuckahoe! I wanted information on how RAG and Live Intenet Search work with LLMs. I chose Gemini 2.5 Pro Reasoning, Math & Code for the task. The final example included as a follow up to expand on real time search included my physical location, which is freely...
Comparing LLM responses
LLM Responses compared I thought a nice exercise would be to take a relatively simple prompt and assess how the Closed and Open models currently available compare. This is the prompt that I used: <PROMPT> I’m taking my daughter to an oral surgeon today to...
Perplexed-ity?
Perplexed-ity? I came across this blog post from Cloudfare: Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives I've read and heard a lot of positive things about Perplexity's Comet browser. I want to like them and I want to cheer...