Humanity’s Last Exam
Benchmarks are interesting.
Here’s the deep thought – at what point in the overall benchmark process will AI inject bias into the benchmark test? And to what end? Maybe not so deep a thought.
Humanity’s Last Exam has been bantered about extensively. Here’s a great place to catch up on it: Humanity’s Last Exam
My musings: check out the crazy difficulty of the questions:
So 2500 questions of this caliber of difficulty. The top AI models hit 20% accuracy in answering.
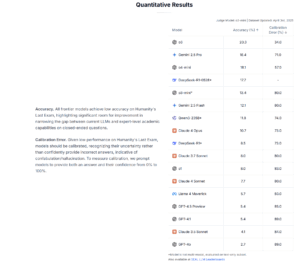
I would also note the Calibration Error, which is affirms that “ Given low performance on Humanity’s Last Exam, models should be calibrated, recognizing their uncertainty rather than confidently provide incorrect answers, indicative of confabulation/hallucination. To measure calibration, we prompt models to provide both an answer and their confidence from 0% to 100%. ” The better performing models – OpenAI o3 and o4-mini and Gemini 2.5 Pro – also have better Calbration Error numbers.
Save the manuals, always – AppleWorks 6
AppleWorks 6 I know nothing of AppleWorks 6 or FileMaker Pro 7. However, I was spending time recently going through old digital photos and came across some pics of stuff I was decluttering when my Dad moved from independent living to assistant living back in 2018. I...
AI Action plan, and stuff
AI Action plan Here ya go folks - this is the current administration's AI Action Plan: https://www.ai.gov/action-plan Here are some words from the current administration about preventing "woke AI" in the federal government...
Subscribed to One Useful Thing
One Useful Thing is the name of Ethan Mollick's substack newsletter. Ethan is the Co-Director of the Wharton Generative AI Labs. Wharton Generative AI Labs has lots of good information including a prompt library: https://gail.wharton.upenn.edu/prompt-library/ Check...
“Accumulation of Cognitive Debt”
There's an article published at MIT that studied "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task https://arxiv.org/abs/2506.08872 This blog post was pitched as a rebuttal of sorts to the MIT study - definitely...
The upside of AI
Positive thoughts? I came across two older items last week that really made me feel good about Artificial Intelligence and some of the good aspects and possibilities. Like most people grounded in reality, the very impact of AI's disruption on the job front and...
That “aha!” moment – a simple image
I finally committed to the "Plus" ($20 a month) version of ChatGPT and have been finding more and more things to use it for, and trying my best not to use it as lazy google. Hum de dum and I'm looking at making an AI Policy for TQuist, as well as provide information...
Anthropic’s AI Fluency course
Here's the link to Anthropic's AI Fluency course: https://www.anthropic.com/ai-fluency